
Depuis près de quarante ans, les spécialistes de la section GEO compulsent les photos aériennes de swisstopo et en tirent des informations sur l’utilisation et la couverture du sol pour plus de 4 millions de points d’échantillonnage. Ces données constituent la source d’information de la statistique de la superficie qui fournit des indications détaillées et précises sur l’état et le développement de l’occupation du territoire en Suisse.
La méthodologie a subi différentes évolutions techniques durant cette période de production, passant de photographies aériennes analogiques stéréoscopiques au numérique à haute-résolution. Depuis 2013, l’objectif est de mener l’enquête de manière continue, avec une périodicité de six ans et une publication annuelle. Pour relever les défis que cela implique, une interprétation assistée par un système de détection des changements et reconnaissance de formes sur les images aériennes est déterminant.
Une étude de faisabilité réalisée en 2017 a permis de définir la vision d’un nouveau processus intégrant à la fois l’intelligence artificielle (IA) et l’interprétation visuelle d’images aériennes par des experts, en vue d’une classification partiellement automatisée. Un projet de révision de la méthodologie a ensuite été lancé en 2018 afin de soutenir les futurs relevés de la statistique de la superficie. Un outil IA a été développé dans le cadre d’un sous-projet nommé ADELE (pour Arealstatistik Deep Learning), avec pour objectif de développer les méthodes d’apprentissage entièrement ou semi-automatiques issues des technologies d’apprentissage machine. ADELE a fait dès le début partie des projets de statistiques expérimentales de l’OFS. Le transfert en production résultant de ces travaux a été validé le 7 juillet par le conseil de direction.
Avec le soutien d’une entreprise externe, la nouvelle plateforme informatique a été développée à l’OFS de manière agile par la méthode SCRUM. Elle se compose d’une application centrale gérant la visualisation stéréoscopique et la saisie des données d’interprétation visuelle, complétée de l’outil IA.

© Carole Greppin / OFS
L’outil IA a été affiné en étroite collaboration avec la section METH et le soutien de l’Université de Neuchâtel, sur la base d’un prototype réalisé sur mandat par un consortium formé de la Fachhochschule Nordwestschweiz et ExoLabs Gmbh. Le transfert en production a dû répondre à une liste de critères requis par le conseil de direction.
Les étapes automatisées du processus d’interprétation consistent en une détection des changements par rapport au dernier relevé, suivi d’une classification de l’utilisation (LU) et de la couverture (LC) du sol. Le gain de productivité escompté par son utilisation est, dans un premier temps, avant tout réalisé grâce la détection du changement. Une classification partiellement automatisée sera également possible dans un deuxième temps, une fois les premiers résultats analysés.
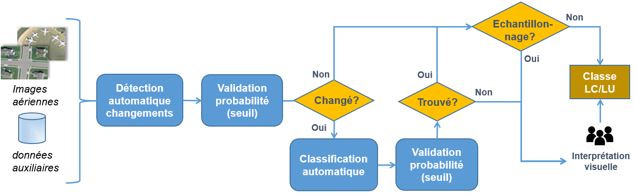
Une interprétation visuelle d’un point d’échantillonnage par des experts est prévue à chaque fois que les probabilités de classification ou de détection de changements automatiques, estimées par l’algorithme, sont inférieures à des seuils préétablis. Un échantillon de contrôle permet de plus un suivi de la qualité de la prédiction.
ADELE intègre trois composants principaux:
- Un outil pour préparation des données permettant de relier les images aériennes de swisstopo (données primaires) aux diverses sources de données secondaires utilisées pour la classification: altitude, hauteur de la végétation, mensuration officielle, surfaces agricoles, topographie et images satellites.
- Un système de réseaux neuronaux convolutifs (ou convolutional neural networks – CNN), dont le deep learning est un cas particulier, bien adaptés à la classification d’images pour lesquelles les données d’apprentissage sont disponibles en très grande quantité. Le rôle des CNN est d’extraire des éléments caractéristiques des images aériennes pour les retranscrire sous la forme de vecteur de prédictions, fournissant ainsi une pré-classification de l’utilisation et la couverture du sol.
- Un système de classification basé sur un algorithme d’apprentissage machine dit des «forêts aléatoires» (ou random forest – RF). Ce système, dont un des avantages est de pouvoir ingérer des données hétérogènes, permet de relier les données issues des CNN avec les données secondaires.
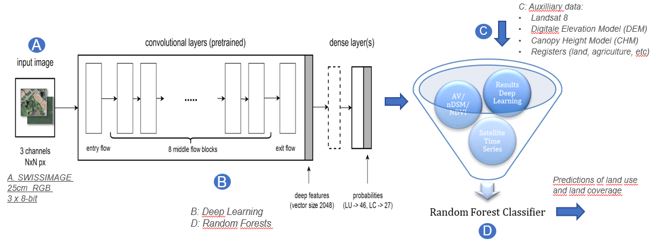
La figure suivante présente le fonctionnement général d’ADELE. La première étape (A et B) est utilisée pour la pré-classification par CNN. La deuxième étape (D) met en œuvre l’étape RF pour la fusion des données auxiliaires (C), permettant d’améliorer considérablement la précision globale des prévisions. Le vecteur final (D) contient les prédictions finales de la classification.
Avant d’être utilisable dans le processus d’interprétation, l’outil IA doit être entraîné par une étape d’apprentissage machine (ou machine learning) se fondant sur des approches mathématiques et statistiques pour donner à l’ordinateur la capacité de générer un modèle à partir de données déjà catégorisées.
Nous avons pu tirer quelques leçons de ce projet dont l’objectif est de soulager l’humain d’une partie des tâches les plus répétitives. Car l’intelligence artificielle et les algorithmes mis en œuvre ne remplacent pas le travail des experts dont les compétences restent inégalables pour distinguer les cas difficiles.

Le potentiel d’innovation pour l’OFS dans l’application de l’IA au traitement des images a été prouvé, mais il reste à mesurer sa valeur ajoutée durant la prochaine enquête. Il permet une détection de changement efficace des scènes d’images aériennes et une classification précise dans une majorité de cas, ouvrant ainsi la voie à une automatisation partielle de la statistique de la superficie, ce qui permet d’entrevoir de nouvelles possibilités, comme une densification spatiale et/ou temporelle. En outre, les compétences acquises au travers du projet et plus tard durant la phase d’exploitation pourraient permettre de développer de nouveaux produits.
Enfin, les nombreux échanges avec les partenaires externes et internes, notamment la section METH et le groupe de travail New Data Science (désormais la section DSCC), ont été très bénéfiques et montrent que le travail en réseau est indispensable pour maîtriser la complexité des technologies actuelles.